Seed selection¶
During the assembling process, to focus on a specific sequence, the mitochondrial genome, the chloroplast genome or the nuclear rDNA, the ORGanelle ASeMbler initiates the assembling from a subset of reads supposed to belongs the targeted sequence.
The seed selection process aims to select this read subset. Reads are selected because they present sequence similarity with genetic elements known to be present on the targeted sequence.
Two kind of genetic elements can be used for selecting these reads:
Protein encoding genes
DNA sequences known to be present on the target sequence.
These genetics elements will be further named seeds. When prtein encoding genes are used as seeds, the protein encoded sequence have to be used rather than the nucleic gene sequence. This allow to be more sensitive during the read selection and to use less phylogenetically closely related species sequence as probe. As example the protChloroArabidopsis seeds set provided with the buildgraph command is constituted of 47 chloroplastic protein sequences from Arabidopsis thaliana. It allows to initiate the assembling of most of the plant chloroplaste genomes.
The ORGanelle ASeMbler uses an algorithm similar, but simpler than the one used by BLAST and based on an Aho Corasick automata.
Seed sequences are splitted in short words (kmer). The size of the words kup is set by default to four for protein sequences and to twelve for DNA sequences. This default size can be set up using the –kup option of the buildgraph command.
When protein sequences are used as seeds, the kmers are back-translated to DNA according to all the NCBI genetic codes. Consequently a single proteic kmer will be converted in a set of DNA words allowing to take into account the genetic code degeneracy.
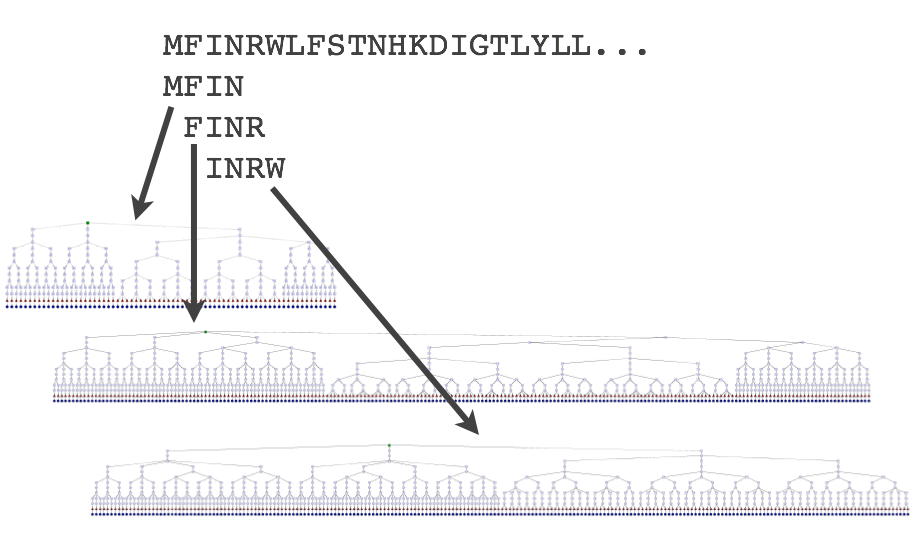
Figure 1: Protein sequences are splitted in short overlaping words.¶
Each small word is back-translated to DNA, reverse-complemented and inserted into the Aho-Corasick automata. You can see for each protein word a tree representing the Aho Corasick automata strucuture corresponding to it. Each branch of these trees correspond to a DNA work issued from the back-translation process and the reverse complement of these DNA words. This give you an idea of the number of DNA words generated for each peptide.
The automata is filled